机器学习算法-决策树
决策树
决策树是一种非常常用的传统机器学习算法,相较于贝叶斯、svm等其他算法,决策树具有一些明显的优势,就是在构建决策树的过程中不需要任何的领域知识,也不需要复杂的参数设置。这就使得决策树更适合于探测式的知识发现。
决策树的算法思想
通俗版
参考一篇文章的介绍,决策树的分类思想可以类比成相亲,比如说一个女孩子的妈妈托七大姑八大姨要给自己介绍一个男朋友,便有了下面的对话:
1 | 女儿:多大年纪了? |
这这段对话就完整表达了一个决策过程,形成一个典型的分类树决策。
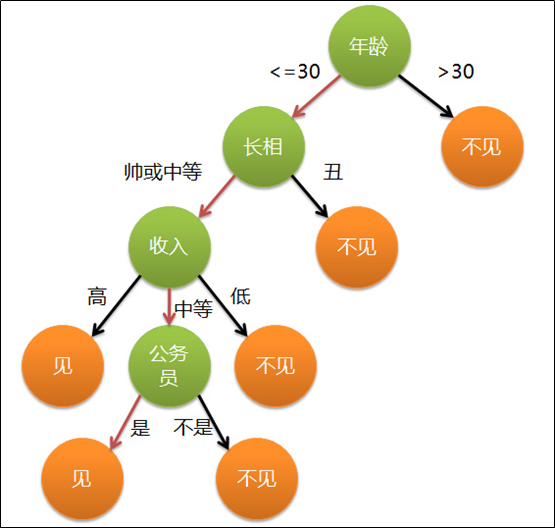
对于女孩决定是否见约会对象的策略中:
绿色代表判断条件
橙色代表决策结果
箭头表示决策途径
图中红色箭头表示了上面例子中女孩的决策过程。这幅图基本可以算是一颗决策树,说它”基本可以算“是因为图中的判定条件没有量化,如收入高中低等等,还不能算是严格意义上的决策树,如果将所有条件量化,则就变成真正的决策树了。
概念版
从定义上来说,决策树是一个树结构(可以是而二叉树或非二叉树),其中每一个非叶子节点表示一个特征属性的判断,每一个分支表示这个特征属性的判断的分支,而每一个叶子存放一个类别。使用决策树进行决策的过程,就是从根节点开始,对待决策问题的特征属性进行判断,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
决策树的构建
我们知道决策树会通过对特征属性的判断,形成分支,最后形成一个树状结构。但这里有一个问题,就是特征分割的前后顺序是怎样决定的。我们还是以女孩子相亲为例,年龄、长相、收入、职业等特征属性到底谁先判断谁后判断呢?
我们内心有一个标准就是:重要的评价标准肯定要先问。决策树也会为每次对特征的判断分割进行计算,找到一个最优解,并以这个最优的特征分割点作为当前的分割点。还是以相亲为例子,女孩子想了一下对相亲对象最重要的要求就是年龄不能超过30岁!所以就会将这个分割点放在最前面。
决策树的分割点选择
决策树的每次分割,都是采用贪婪策略,就是选择特征分割的最优解进行划分。这个最优解的量化方法主要有熵、信息增益、信息增益比、基尼系数等多种方法。对于具体的分割方法,我们一起CART举例,通过伪代码的方法展示分割点的选择过程:
1 | 每个特征维度D: |
熵
熵一种信息论的概念,代表信息的期望。熵不能直接作为特征分割的量化标准。

S:表示一个数据集 t=p+n p:正样本 n:负样本
信息增益
信息增益是熵与条件熵的差值。条件熵是指将数据集进行分割成多个子数据集。并按照各个子数据集占数据集的比例作为权重,计算信息熵和加权和。信息增益是ID3型决策树的分割标准。
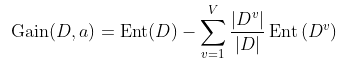
D:表示一个数据集 Dv:按照条件将数据集D划分成V个子数据集,其中的第v个子数据集 V:子数据集个数 Ent(D):D这个数据集的信息熵
信息增益比
当一个数据集被划分成非常多个子数据集,并且每个子数据集中的样本数都非常少时,信息增益中的条件熵就会变得非常小,导致信息增益有偏向性,为了应对这个问题,提出了信息增益比的分割标准。这个标准会引入数据集分割的信息熵,以平衡偏向性的影响。这个分割标准主要用于C4.5决策树中。
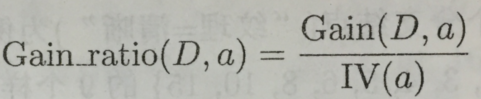
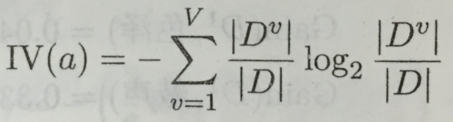
a:表示数据集的分割方法
基尼系数
基尼系数是一种在经济上衡量居民收入差距的常用指标。由于其与熵模型的度量方式非常相近,并且计算简单,因此被用来代替熵的方法。
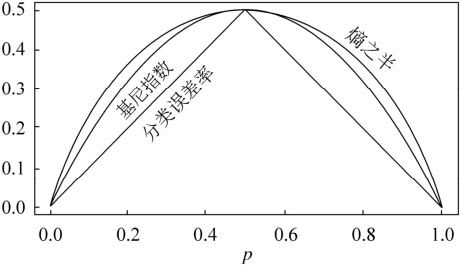
采用基尼系数作为分割标准的决策树是CART,也是目前主要是使用的决策树,普遍应用于bagging和boosting等集成学习的方法当中。同时基尼系数可以看成是信息增益的一阶泰勒展开。
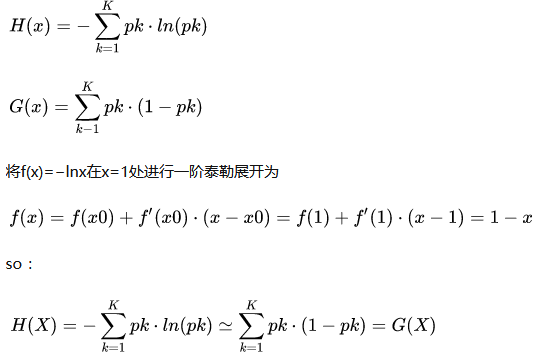
需要注意的一点是,基尼系数追求的是最小值,熵相关的分割标准追求的是最大值(加不加负号的区别)。
决策树的分割停止
如果让决策树一直分割下去,最终的结果就是每个叶子节点只有一个样本。这样显然会导致模型复杂度过高以及模型过拟合的问题。因此需要制定策略作为决策树停止分割的条件。
最小样本数阈值
当该分支的样本集个数小于最小样本数时,分支停止分裂。
熵的阈值
熵过小时,如果数据复杂度不大,就不需要继续分裂了。极端情况就是待分裂的样本都是同一类,这时候熵为0。
决策树深度阈值
决策树的深度,决策树的深度就是所有叶子节点的最大深度,子节点比父节点深度加1,当某一分支的深度达到深度阈值,该分支停止分裂。
无可分裂特征
当所有特征都是用完时,没有可以继续分裂的属性,就将当前节点作为叶子节点,并停止该分支的分裂。
决策树的剪枝
决策树的剪枝一般分为两种方法,分别是预剪枝和后剪枝。
预剪枝
预剪枝就是在决策树的构建过程中进行剪枝,在构造的过程中对节点进行评估,如果对某个节点进行划分时不能带来准确性的提升(损失函数的降低),那么对这个节点进行划分就没有意义,这时就会把当前节点作为叶节点,不对其进行划分。预剪枝容易导致欠拟合。
这里需要明确的是准确性的提升,就是对比未分割数据集和已经分割完成后,验证集之间的准确性。
(0 1 0 1 1) -->验证集
(1 1 1 0 0) -->训练集
/
/
(0 0 1) (1 1) -->验证子集
(0 0 0) (1 1) -->测试子集
划分前验证集的准确率:五个样本中,因为“1”样本较多,因此验证集的准确率=3/5=60%
划分后验证集的准确率:左子集有两个判断正确,右子集有两个判断正确,因此验证集的准确率=4/5=80%
后剪枝
后剪枝就是在生成决策树之后再进行剪枝。通常会从决策树的叶子节点开始,逐层向上对每个节点进行评估。如果剪掉这个节点子树,与保留该节点子树在分类准确性上差别不大,或者剪掉该节点子树,能在验证集中带来准确性的提升,那么就可以把该节点子树进行剪枝。
决策时的实现方法
可以使用sklearn,或者自己写。